Trust laundering is when attackers exploit a domain's established reputation to initiate an attack chain, bypassing email gateways and conventional security controls. The actual attacker infrastructure doesn't appear in anything a scanner evaluates or a user sees until the final hop, if it appears at all. This makes it one of the highest-reward, lowest-cost techniques in the modern phishing arsenal, and one of the least discussed.
A domain's reputation is built on interlocked signals: age and sending history, whether a domain has been around for decades or days, sending patterns and traffic growth, user engagement, and the authentication posture behind it: SSL certificates, DMARC records and Safe Browsing history. Attackers inherit all of this instantly by generating a single redirect slug on a platform that spent years earning it.
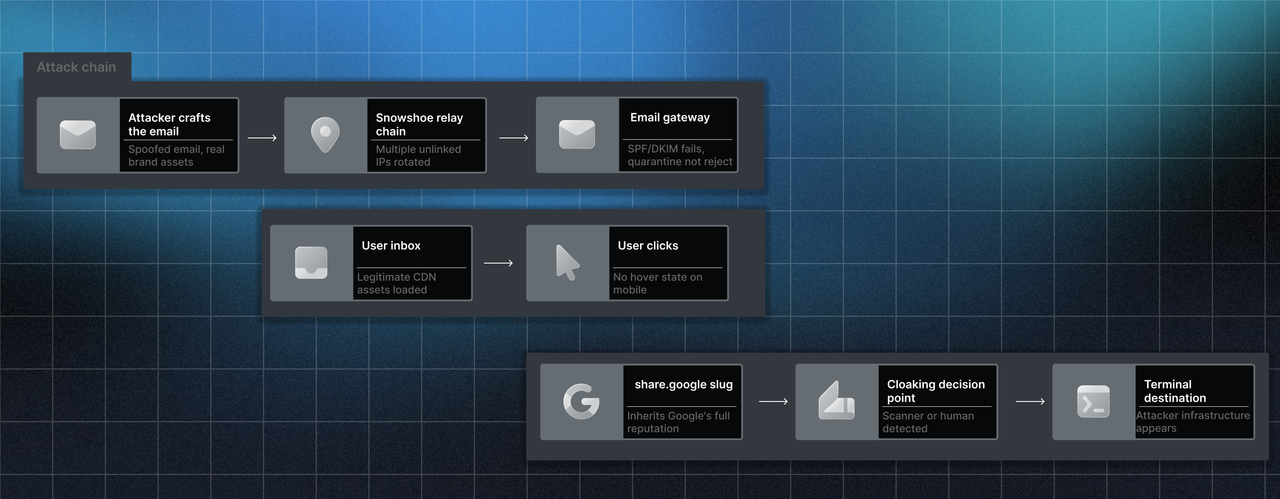
How the Trust Laundering Attack Works
- The First Hop: The attacker generates a redirect slug on a high-reputation platform (e.g., Google, Microsoft). This satisfies allowlist checks, preventing the email from being flagged at the gateway.
- The Second Hop: The message resolves to a trusted domain, defeating sandbox detonation since the security tool sees only the legitimate root infrastructure.
- The Third Hop: The chain burns click-time URL inspection by using legitimate redirectors, ensuring every layer of legitimate infrastructure neutralises a specific detection mechanism.
- The Terminal Hop: The attacker's infrastructure appears only at the final destination, after every inspection layer has already cleared the request.
The Problem: Features as Vulnerabilities
Legitimate tools and software have built-in redirect capability that emerges indirectly as a product feature. A URL shortener without redirect is not a URL shortener. A CDN that will not serve arbitrary content is not a CDN. The feature and the vulnerability are the same thing, which is the core reason trust laundering cannot be patched at the platform level without effectively destroying the product.
2.1 URL Shorteners
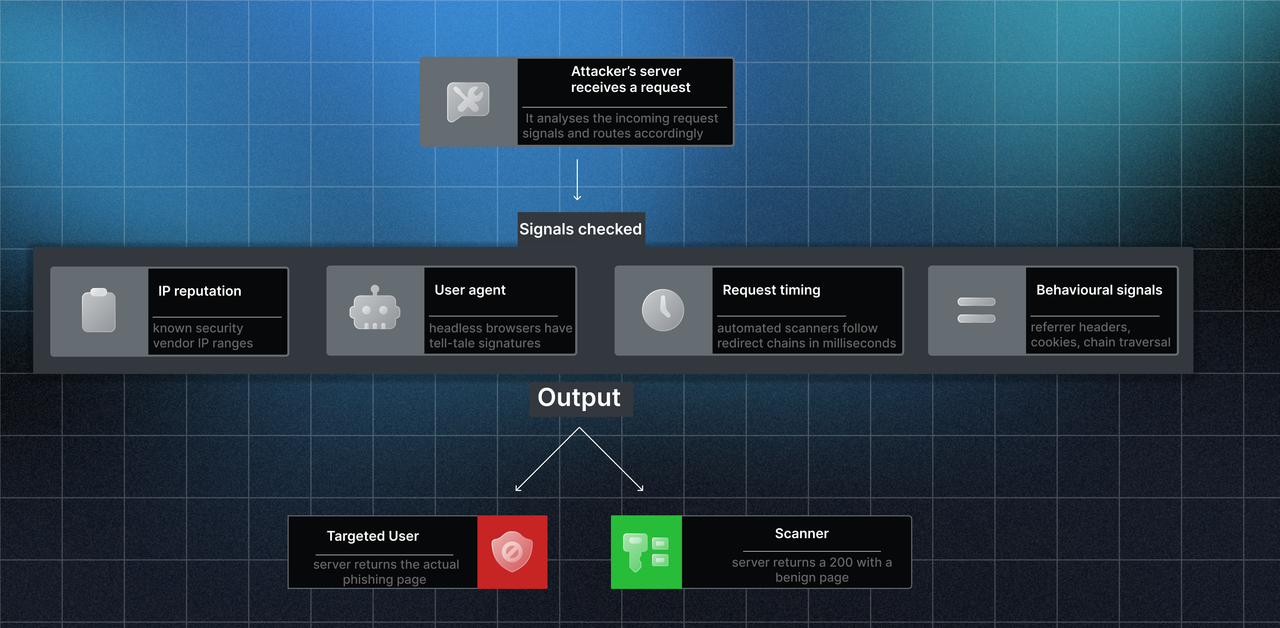
Platforms like bit.ly, TinyURL, and Google's share.google generate a short slug that maps to a destination URL. From a trust laundering perspective, these are the most efficient attack surfaces. A new slug is free, carry zero history for blocklists, and are recycled rapidly so reactive takedown arrives too late. URL shorteners also use cloaking: the server analyses the request and serves a benign page to security scanners while showing the phishing page to real users.
2.2 Cloud Storage and File Sharing
Cloud storage platforms: Google Drive, SharePoint, OneDrive, Dropbox generate unique URLs under their own domain to serve files. A malicious HTML file on SharePoint is indistinguishable from a legitimate document to reputation-based systems. Attackers have used thousands of compromised Microsoft tenants to distribute sharepoint.com links which pass SPF, DKIM, and DMARC cleanly, achieving 7x higher click rates due to user familiarity.
2.3 CDNs and App Hosting
Content delivery networks (Cloudflare Workers, AWS, Heroku) host arbitrary code under their root domain. Unlike simple redirects, these can execute full application logic: session fingerprinting, CAPTCHA challenges, and AiTM (adversary-in-the-middle) relay pages that intercept MFA session cookies in real time.
Why Traditional Security Misses It
Existing controls were designed around the assumption that a malicious link eventually touches a malicious domain with a bad reputation signal. Domain allowlists and reputation systems assign trust at the domain level, not the content level. Blocklists are reactive by design; they catch the last campaign, not the current one. Sandbox detonation is defeated by cloaking, where the server identifies the sandbox environment and returns a clean response. On mobile, the attack surface widens further because touchscreens lack a hover state, making URL inspection physically unavailable to most users.
Why It Cannot Be Patched
Structural remediation would require either removing the redirect/hosting feature or performing real-time, automated content evaluation of every destination at a scale (trillions of requests) and latency that is not currently achievable. Reactive takedown works after the campaign has completed.
The Behavioural Signal That Gives It Away
The failure of existing controls is that they evaluate the link in isolation. Effective detection requires a local, user-level behavioural baseline. An attacker can borrow Google's reputation, but they cannot borrow the fact that a specific user has never visited a particular destination before. A zero-hour slug on share.google is orignal at the domain level but immediately anomalous at the user-behaviour level when it resolves to a destination the user has never seen.
How to Prevent It in Practice
Effective detection requires moving the evaluation point from the email to the browser, from the domain to the destination, and from global reputation to individual behavioural context.
Fortulio operates at this layer. Rather than evaluating domains against global reputation signals, Fortulio resolves the full redirect chain in the user's real browser and evaluates the terminal destination against that specific user's behavioural baseline. A link through share.google that resolves to a domain the user has never visited is flagged regardless of the reputation of every intermediate hop.
Conclusion
Trust laundering exploits a structural condition in the internet's trust architecture. It persists because the feature creating the attack surface is the same feature that makes the product work. The only approach not structurally defeated by the technique is detection that operates at the browser level, evaluating where the redirect chain actually terminates against what the user normally does.
References
- LOTS Project. Living Off Trusted Sites. mrd0x.
- Paubox. Attackers use Google services to hide phishing links. March 2026.
- Check Point. 40,000 Phishing Emails Disguised as SharePoint. Dec 2025.
- Microsoft Security Blog. Resurgence of multi-stage AiTM phishing campaigns. Jan 2026.
- Microsoft Security Blog. OAuth redirection abuse. March 2026.
- Proofpoint. Microsoft OAuth App Impersonation. July 2025.
- Barracuda Networks. Frontline security predictions 2026. Nov 2025.
- InceptionCyber. Weaponizing Trust: Google Docs URL in Phishing. July 2025.